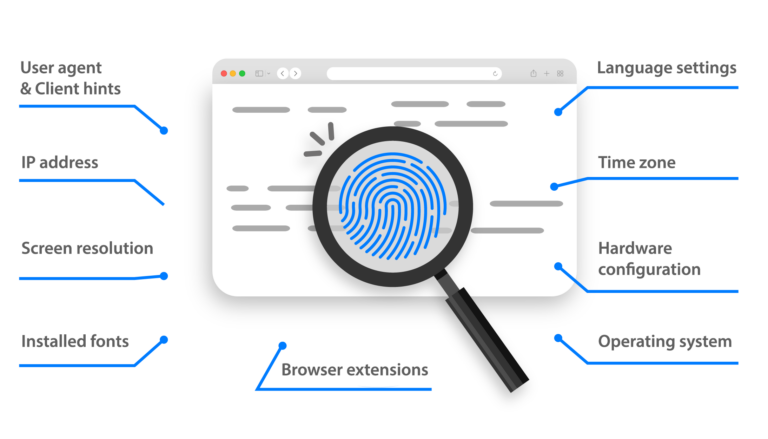
Coletar dados dos resultados de busca do Google é uma técnica de peso para obter dados valiosos do motor de busca mais usado do mundo. Quer você queira obter informações importantes, construir aplicações, ou compilar dados de busca, coletar dados do Google pode trazer enormes benefícios. Este artigo explora os vários aspectos do web-scraping no Google, as ferramentas disponíveis, e como usar de modo eficaz um navegador anti-detecção como o Multilogin para evitar ser detectado e garantir que suas operações corram tranquilamente.
O que é a coleta de dados do Google?
Coletar dados do Google implica extrair dados das páginas de resultados da busca do Google, do Google Maps, e de outros serviços do Google. Esses dados podem ser usados para análise de SEO, investigação dos concorrentes, análise de mercado e mais.
É legal coletar dados do Google?
A legalidade da coleta de dados do Google é complexa. Enquanto os termos de uso do Google proíbem o web-scraping automatizado, o ato em si não é necessariamente ilegal. É importante obedecer as leis e regulamentos locais e usar o web-scraping de forma responsável para evitar problemas legais.
Ferramentas para web-scraping do Google
Ferramentas de coleta de dados do Google
Há diversas ferramentas que podem ajudar com a coleta de dados do Google, variando em complexidade e funcionalidade para responder a diferentes necessidades e níveis de expertise técnica.
Scripts de Python personalizados
Python, com bibliotecas como BeautifulSoup, Scrapy e Selenium, é uma opção muito usada para web-scraping. Essas bibliotecas fornecem ferramentas de peso para extrair dados dos resultados da busca do Google e do Google Maps.
Multilogin: a solução em navegadores anti-detecção
O Multilogin é um navegador anti-detecção que lhe permite gerir diversos perfis e evitar ser detectado enquanto coleta dados do Google. Ele simula o comportamento humano e usa IPs residenciais de alta qualidade para impedir o Google de identificar e bloquear suas atividades de web-scraping.
Web-scraping e APIs do Google: limites e considerações
O Google oferece APIs como a API do JSON da Busca Personalizada e a API do Google Places para acessar dados de busca e localização. Acontece que essas APIs têm limites e restrições de uso, o que pode complicar projetos de coleta de dados mais amplos. Usar o Multilogin junto com scripts de web-scraping personalizados pode ajudá-lo a contornar essas limitações e acessar os dados de que você precisa sem chegar nos limites das APIs.
Você precisa de proxies especiais para coleta de dados do Google?
Quando se trata de fazer web-scraping dos resultados da busca do Google, é altamente recomendado que você use proxies. Eis porque:
Evitando detecção e banimentos
O Google tem sistemas sofisticados para detectar e bloquear o web-scraping automatizado. Se várias solicitações vierem do mesmo endereço de IP em um período de tempo curto, o Google pode rapidamente marcar e banir o IP. Os proxies ajudam a distribuir suas solicitações por vários endereços de IP, reduzindo em muito o risco de detecção e garantindo que suas atividades de web-scraping não sejam interrompidas.
Garantindo o anonimato
Os proxies mascaram seu endereço de IP real, deixando-o anônimo e dificultando que o Google rastreie as solicitações e chegue até você. Isso é crucial para manter a integridade de suas operações de coleta de dados, especialmente se você precisar recolher grandes volumes de dados.
Acessando dados com restrição geográfica
Os resultados da pesquisa do Google podem variar de acordo com a localização geográfica do usuário. Os proxies permitem simular solicitações vindas de diferentes locais, dando-lhe acesso a resultados de pesquisa de localizações específicas ou com restrições geográficas. Isso é particularmente útil para empresas que estão fazendo pesquisas de mercado ou análises de concorrentes em diversas regiões.
Aprimorando a eficiência do web-scraping com o Multilogin
O Multilogin aprimora seus esforços de web-scraping integrando-se perfeitamente com proxies residenciais de alta qualidade. Veja como o Multilogin e os proxies trabalham em conjunto para garantir uma coleta de dados eficiente e que não seja detectada pelo Google:
Gerenciamento de perfil: o Multilogin permite que você crie e gerencie vários perfis de navegador, cada um com suas próprias configurações de proxy. Isso garante que suas solicitações sejam distribuídas por diferentes endereços de IP.
Comportamento semelhante ao humano: o Multilogin imita o comportamento de navegação de usuários humanos, reduzindo ainda mais o risco de detecção.
Gerenciamento de sessões: gerencie com eficiência sessões e cookies para realizar operações de coleta de dados contínuas, sem interrupções.
Abordagem unificada para coletar dados do Google Maps e do Google Sheets com o Multilogin
O web-scraping do Google Maps e do Google Sheets pode agilizar a extração e integração de dados para seus projetos. Veja como você pode coletar dados de ambas as plataformas de forma eficiente usando o Multilogin:
Configuração do Multilogin: crie vários perfis de navegador com configurações distintas para diversificar suas atividades de coleta e evitar ser detectado.
Desenvolvimento de scripts: use Python com bibliotecas relevantes (Selenium para o Google Maps, gspread para o Google Sheets) para desenvolver seus scripts de web-scraping. Essas bibliotecas simplificam a interação com os respectivos serviços do Google.
Simule interações humanas: garanta que seus scripts executem as ações de uma forma que parece humana, contornando assim os mecanismos anti-coleta do Google. Isso inclui deixar os movimentos do mouse, cliques e padrões de digitação totalmente aleatórios.
Gerenciamento de sessão e cookies: utilize os recursos avançados de gerenciamento de sessão e cookies do Multilogin para realizar várias tarefas de coleta de dados simultaneamente sem ser detectado.
Execução e monitoramento contínuo: execute seus scripts dentro do Multilogin, ficando de olho e fazendo os ajustes necessários para melhorar o desempenho e a fiabilidade.
Seguindo essas etapas otimizadas, você consegue coletar dados do Google Sheets e do Google Maps com eficiência, aproveitando os potentes recursos do Multilogin para garantir que suas operações ocorram tranquilamente e não sejam detectadas.
Boas práticas para coletar dados dos resultados da busca do Google
Use o Multilogin para evitar ser detectado
Para coletar dados do Google sem ser detectado, siga estas boas práticas e use ferramentas como o Multilogin:
Imite o comportamento humano: deixe os movimentos do mouse, cliques e padrões de digitação totalmente aleatórios
Alterne os endereços de IP: use proxies residenciais fornecidos pelo Multilogin para alternar endereços de IP, evitando assim ser detectado.
Gerencie perfis do navegador: use o Multilogin para criar e gerenciar múltiplos perfis do navegador, cada um com configurações próprias.
Respeite os limites de chamadas: evite enviar demasiadas solicitações em pouco tempo, para não ativar as medidas anti-bot do Google de uma mesma conta.
Monitore o desempenho: confira regularmente o desempenho dos seus scripts de web-scraping e faça adaptações conforme necessário.