O web-scraping LinkedIn, ou coleta de dados do LinkedIn, tornou-se uma estratégia de valor inestimável para empresas e profissionais que querem obter novas perspectivas e coletar leads da maior rede profissional do mundo. Seja para geração de leads, pesquisa de mercado ou scraping de vagas de emprego, a coleta de dados do LinkedIn traz enormes vantagens. Neste artigo vamos nos aprofundar nos detalhes do web-scraping LinkedIn, explorar diversas ferramentas e discutir as boas práticas de uso de navegadores como o Multilogin para garantir que suas atividades de web-scraping não sejam detectadas.
O que é o web-scraping LinkedIn?
A coleta de dados do LinkedIn implica extrair dados de perfis do LinkedIn, de anúncios de emprego, de páginas de empresas e de outros elementos da plataforma. Esses dados podem ser usados para diversos fins, incluindo construir bancos de dados de potenciais clientes, analisar tendências do setor e até criar listas de empregos para sites de vagas de trabalho.
Por que fazer scraping do LinkedIn?
Geração de leads
Um dos principais motivos para o scraping LinkedIn é a geração de leads. Os negócios podem compilar listas de potenciais clientes ou parceiros extraindo detalhes de perfis do LinkedIn, como nomes, cargos, nomes de empresas e informações de contato.
Pesquisa de mercado
Ao coletar dados do LinkedIn, as empresas podem obter novas perspectivas sobre tendências do setor, atividades de concorrentes e a dinâmica geral do mercado. Isso pode embasar decisões estratégicas e estratégias de marketing.
Scraping de empregos
Recrutadores e sites de vagas geralmente usam o scraping LinkedIn para reunir anúncios de emprego de várias empresas. Isso ajuda a compor listas de vagas abrangentes, o que pode atrair quem está à procura de emprego para suas plataformas.
Ferramentas de scraping do LinkedIn
Várias ferramentas podem ajudar com a coleta de dados do LinkedIn, cada uma com recursos e aptidões distintos. Eis aqui algumas ferramentas bastante usadas para scraping do LinkedIn que você pode programar em um navegador como o Multilogin:
Scripts Python personalizados: Python oferece bibliotecas de peso como BeautifulSoup, Scrapy e Selenium que podem ser usadas para a coleta de dados do LinkedIn. Ao programar scripts Python personalizados, você pode adaptar seu processo de scraping para atender a necessidades específicas, automatizar tarefas e lidar com grandes volumes de dados de forma eficiente.
Extensões do navegador: Extensões de navegador como o Web Scraper podem ser integradas ao Multilogin, permitindo que você configure tarefas de scraping diretamente desde a interface do navegador. Essa abordagem é de fácil uso e eficaz para tarefas de coletas de dados menores.
APIs: A API oficial do LinkedIn pode ser usada para scraping dentro dos limites dos termos de uso da plataforma. Embora isso tenha suas limitações, integrar a API do LinkedIn ao Multilogin permite que você extraia dados de forma programática, ao mesmo tempo em que se mantém em conformidade com as políticas do LinkedIn.
Boas práticas para web-scraping LinkedIn
Use o navegador Multilogin
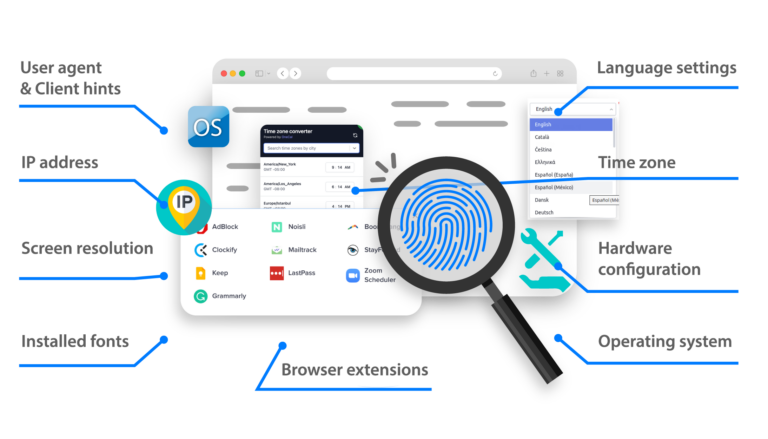
O LinkedIn tem mecanismos sofisticados para detectar e bloquear atividades de coleta de dados. Usar um navegador como o Multilogin pode ajudar você a evitar ser detectado e a gerenciar diversas contas sem levantar suspeitas, simplesmente imitando comportamentos de navegação humanos.
Alterne os endereços de IP
A rotação de IPs é essencial para uma coleta de dados de sucesso no LinkedIn. Implementar uma rotação de IPs em seus scripts de coleta ajuda a evitar bloqueios da parte do LinkedIn.
Respeite os termos de uso do LinkedIn
Enquanto a coleta de dados pode trazer vantagens, é importante respeitar os termos de uso do LinkedIn. Evite coletar quantidades excessivas de dados em um período curto e certifique-se de que você não está infringindo a privacidade dos usuários.
Use proxies
Os proxies adicionam uma camada extra de anonimato às suas atividades de scraping. Os proxies residenciais são especialmente eficazes, pois têm menos probabilidade de serem marcados pelo LinkedIn.
Gerencie cookies e cache
Gerenciar seus cookies e cache com regularidade pode impedir que o LinkedIn identifique seus padrões de coleta de dados. O Multilogin fornece recursos para gerir cookies e cache de forma eficaz, garantindo assim que as operações de coleta de dados sejam feitas sem percalços.
Como o Multilogin melhora o scraping LinkedIn
O Multilogin é um navegador que ajuda a gerenciar várias contas do LinkedIn sem ser detectado. Veja como ele pode contribuir para seus esforços de coleta de dados no LinkedIn:
Gerenciamento de perfil
O Multilogin permite que você crie e gerencie vários perfis de navegador, cada um com endereço IP, cookies e histórico de navegação distintos. Isso ajuda a simular diferentes usuários e evitar ser detectado.
Comportamento semelhante ao humano
Um dos principais diferenciais do Multilogin é sua capacidade de imitar o comportamento de navegação de um ser humano. Isso inclui deixar os movimentos do mouse, cliques e uso de teclas totalmente aleatórios, fazendo com que suas atividades de coleta de dados pareçam estar sendo feitas por uma pessoa.
Integração perfeita
O Multilogin se integra perfeitamente a várias ferramentas de scraping do LinkedIn, aumentando a eficácia delas e reduzindo o risco de que as contas sejam banidas. Quer você esteja usando scripts Python personalizados, extensões de navegador ou APIs, o Multilogin garante que suas atividades de scraping passem despercebidas.
Estudo de caso: uso do Multilogin para coleta de vagas de emprego no LinkedIn
Imaginemos um cenário em que uma agência de empregos quer coletar postagens de oferta de emprego do LinkedIn para criar uma seleção de vagas abrangente. Veja como eles podem fazer isso usando o Multilogin:
Etapa 1: Configuração do Multilogin
A agência configura vários perfis de navegador no Multilogin, cada um com um endereço de IP e ambiente de navegação distintos. Isso garante que suas atividades de coleta sejam distribuídas por contas diferentes, minimizando o risco de detecção.
Etapa 2: Escolha de um método de coleta
A agência decide usar scripts Python personalizados para as tarefas de coleta de dados, devido à flexibilidade e ao controle que esses scripts oferecem. Eles integram esses scripts ao Multilogin para aumentar seu anonimato.
Etapa 3: Configuração das tarefas de coleta
Usando bibliotecas Python como BeautifulSoup e Selenium, a agência configura as tarefas de web-scraping para extrair postagens de vagas do LinkedIn. Eles configuram parâmetros para que sejam coletados dados como cargos, nomes de empresas, locais e descrições de cargos.
Etapa 4: Monitoração e adaptação
À medida que as tarefas de scraping são executadas, a agência monitora os resultados e ajusta os parâmetros conforme necessário. Eles usam os recursos do Multilogin para gerenciar cookies e caches, certificando-se assim de que as atividades de scraping continuarão sem ser detectadas.
Etapa 5: Agregação de dados
Os dados coletados são agregados em um banco de dados, que é usado para construir a lista de vagas. A agência garante que os dados sejam atualizados regularmente agendando novas coletas de dados periódicas.