对于希望从全球最大的专业网络中收集见解和销售线索的企业和专业人士来说,LinkedIn数据抓取(或LinkedIn网络数据抓取)已成为一种宝贵的策略。无论是潜在客户拓展、市场调研还是职位抓取,LinkedIn数据抓取都能带来巨大的优势。在本文中,我们将深入探讨LinkedIn数据抓取的详细信息,探索各种工具,并讨论使用Multilogin等防检测浏览器的最佳方法,从而确保数据抓取行为不被发现。
什么是LinkedIn数据抓取?
LinkedIn数据抓取指的是从LinkedIn 个人资料、职位招聘信息、公司页面和平台的其他元素中提取数据。这些数据可用于多种目的,包括建立潜在客户数据库、分析行业趋势,甚至为招聘网站汇总职位招聘信息。
为什么抓取LinkedIn数据?
潜在客户拓展
抓取LinkedIn数据的其中一个主要原因是拓展潜在客户。企业可以通过从LinkedIn个人资料中提取包括姓名、职位、公司名称和联系方式等详细信息,从而整理出潜在客户或合作伙伴名单。
市场调研
通过抓取LinkedIn数据,企业可以深入了解行业趋势、竞争对手活动和整体市场动态,有助于制定战略决策和营销策略。
职位抓取
招聘人员和招聘网站通常使用LinkedIn数据抓取来收集不同公司的职位招聘信息。这有助于构思全面的招聘信息,从而吸引求职者访问他们的平台。
LinkedIn数据抓取工具
要进行LinkedIn数据抓取,可借助几个工具,它们都具有独特的作用和功能。如下是进行LinkedIn数据抓取的几个热门工具,您可以在Multilogin等防检测浏览器中对它们进行编写:
自定义Python脚本:Python提供功能强大的库,如BeautifulSoup、Scrapy和Selenium,可用于抓取LinkedIn数据。通过编写自定义Python脚本,您可以定制自己的数据抓取流程,以满足特定需求,实现任务自动化,并高效处理大量数据。
浏览器扩展:包括Web Scraper在内的浏览器扩展可集成到Multilogin,使您能够直接从浏览器界面配置任何数据抓取任务。这种方法既方便用户使用,也适用于较小规模的数据抓取任务。
API:LinkedIn的官方API可用于在其服务条款范围内进行数据抓取。尽管存在一定的局限性,但将LinkedIn的API与Multilogin集成不仅能让您以编程方式提取数据,同时不违反LinkedIn的政策。
LinkedIn网络数据抓取最佳方法
使用防检测浏览器
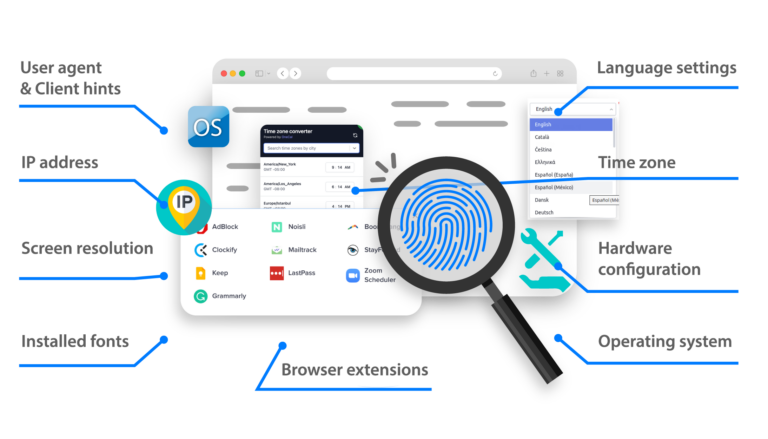
LinkedIn拥有严密的机制来检测和拦截数据抓取行为。Multilogin等防检测浏览器提供多种功能帮助您避开检测,包括模仿真人浏览行为、管理多个账号且不引起网站注意。
轮换IP地址
IP地址轮换是成功进行LinkedIn数据抓取的关键。在数据抓取脚本中实施IP地址轮换能避免被LinkedIn拦截。
遵守LinkedIn服务条款
虽然数据抓取可以为您带来好处,但遵守LinkedIn的服务条款同样重要。请避免在短时间内抓取过多数据,并确保不侵犯用户隐私。
使用代理
代理能进一步将数据抓取行为隐匿起来。住宅代理效果显著,因为它们被LinkedIn注意到的风险更低。
处理Cookie和缓存
定期处理Cookie和缓存可以防止LinkedIn发现您的数据抓取行为。Multilogin提供有效处理Cookie和缓存的功能,确保数据抓取操作顺利进行。
Multilogin如何提高LinkedIn数据抓取效率?
Multilogin是一种防检测浏览器解决方案,可帮助用户管理多个LinkedIn账号,无需担心检测风险。以下是Multilogin提高LinkedIn数据抓取效率的几项突出功能:
配置文件管理
Multilogin能创建和管理多个浏览器配置文件,每个配置文件都有自己独特的IP地址、Cookie和浏览历史记录。这有助于模拟不同用户的浏览行为,从而避免被检测。
模拟真人行为
Multilogin的其中一个主要功能是模拟真人浏览行为,包括随机鼠标移动、点击和按键输入,这样做能使您的数据抓取行为看起来就像是真人操作。
无缝集成
Multilogin可与各种LinkedIn数据抓取工具无缝集成,从而提高效率并降低账号被禁的风险。无论您使用的是自定义Python脚本、浏览器扩展还是API,Multilogin都能确保您的数据抓取行为不引起网站注意。
案例研究:通过Multilogin进行LinkedIn职位抓取
试想一下:一家招聘机构希望抓取LinkedIn上的职位招聘信息,以建立一个全面的招聘网站。以下是他们使用Multilogin来实现这一目标的步骤:
第1步:设置Multilogin
招聘机构在Multilogin中设置多个浏览器配置文件,而且每个配置文件都有独一无二的IP地址和浏览环境。这样可以确保数据抓取活动在不同账号中进行,尽可能降低遭到检测的风险。
第2步:选择数据抓取方式
由于Python脚本拥有灵活性和控制能力,招聘机构使用自定义Python脚本来完成数据抓取任务。为加强匿名性,他们将这些脚本集成到Multilogin中。
第3步:配置数据抓取任务
通过BeautifulSoup和Selenium等Python库,招聘机构为从LinkedIn提取职位招聘信息而配置数据抓取任务。他们设置参数来抓取包括职位名称、公司名称、地点和职位描述等数据。
第4步:监控和调整
随着数据抓取任务的运行,招聘机构会监控抓取结果,并根据需要调整参数。他们使用Multilogin来处理Cookie和缓存,以保证数据抓取活动的隐匿运行。
第5步:数据汇总
最后,招聘机构会将抓取获得的数据汇总到数据库中,用于建立招聘网站。他们通过定期数据抓取任务来保持数据更新。