Thu thập kết quả tìm kiếm của Google là một kỹ thuật mạnh mẽ để thu thập dữ liệu có giá trị từ công cụ tìm kiếm phổ biến nhất thế giới. Cho dù bạn muốn có được thông tin chi tiết, xây dựng ứng dụng hay biên soạn dữ liệu nghiên cứu, việc thu thập dữ liệu của Google có thể cực kỳ có lợi. Bài viết này khám phá các khía cạnh khác nhau của việc thu thập dữ liệu của Google, các công cụ có sẵn và cách sử dụng hiệu quả trình duyệt chống phát hiện như Multilogin để tránh bị phát hiện và đảm bảo hoạt động trơn tru.
Thu thập dữ liệu Google là gì?
Thu thập dữ liệu Google bao gồm việc trích xuất dữ liệu từ các trang kết quả của công cụ tìm kiếm (SERP) của Google, Google Maps và các dịch vụ khác của Google. Dữ liệu này có thể được sử dụng để phân tích SEO, nghiên cứu đối thủ cạnh tranh, phân tích thị trường, v.v.
Thu thập dữ liệu Google có hợp pháp không?
Tính hợp pháp của việc thu thập dữ liệu từ Google rất phức tạp. Mặc dù các điều khoản dịch vụ của Google cấm việc thu thập dữ liệu tự động, nhưng bản thân hành vi này không nhất định là bất hợp pháp. Điều cần thiết là phải tuân thủ luật pháp và quy định của địa phương và sử dụng việc thu thập dữ liệu một cách có trách nhiệm để tránh các vấn đề pháp lý.
Các công cụ cho thu thập dữ liệu web của Google
Các công cụ thu thập dữ liệu web của Google
Several tools can assist with web scraping Google, varying in complexity and functionality to cater to different needs and technical expertise levels.
Các tập lệnh Python tùy chỉnh
Python, với các thư viện như BeautifulSoup, Scrapy và Selenium, là lựa chọn phổ biến để trích xuất dữ liệu web. Các thư viện này cung cấp các công cụ mạnh mẽ để trích xuất dữ liệu từ kết quả tìm kiếm của Google và Google Maps.
Multilogin: giải pháp trình duyệt chống phát hiện
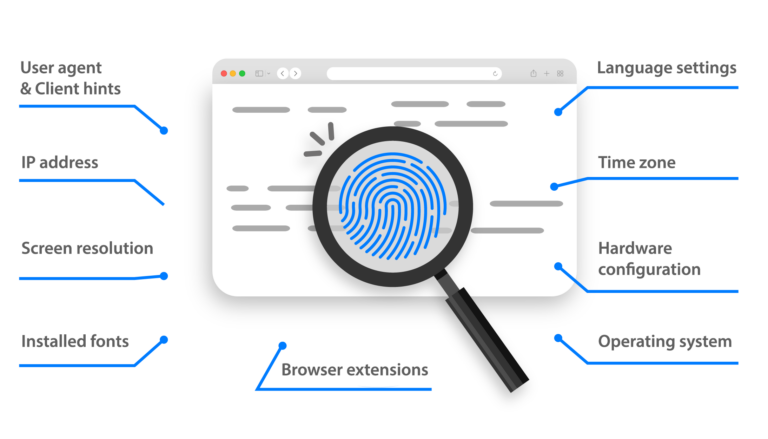
Multilogin is an antidetect browser that allows you to manage multiple profiles and avoid detection while scraping Google. It simulates human behavior and uses high-quality residential IPs to prevent Google from identifying and blocking your scraping activities.
Google Scraping APIs: Limits and Considerations
Multilogin là trình duyệt chống phát hiện cho phép bạn quản lý nhiều hồ sơ và tránh bị phát hiện trong khi thu thập dữ liệu từ Google. Trình duyệt này mô phỏng hành vi của con người và sử dụng IP dân cư chất lượng cao để ngăn Google xác định và chặn các hoạt động thu thập dữ liệu của bạn.
Có cần proxy đặc biệt cho thu thập dữ liệu Google không?
Khi nói đến việc thu thập kết quả tìm kiếm của Google, việc sử dụng proxy được khuyến khích mạnh mẽ. Đây là lý do:
Tránh bị phát hiện và các lệnh cấm
Google có hệ thống tinh vi để phát hiện và chặn việc thu thập dữ liệu tự động. Nếu nhiều yêu cầu đến từ cùng một địa chỉ IP trong thời gian ngắn, Google có thể nhanh chóng đánh dấu và cấm IP đó. Proxy giúp phân phối các yêu cầu của bạn trên nhiều địa chỉ IP, giảm đáng kể nguy cơ bị phát hiện và đảm bảo các hoạt động thu thập dữ liệu của bạn không bị gián đoạn.
Đảm bảo tính ẩn danh
Proxy che giấu địa chỉ IP thực của bạn, cung cấp tính ẩn danh và khiến Google khó theo dõi các yêu cầu trở lại bạn. Điều này rất quan trọng để duy trì tính toàn vẹn của hoạt động thu thập dữ liệu của bạn, đặc biệt là nếu bạn cần thu thập khối lượng dữ liệu lớn.
Truy cập dữ liệu bị giới hạn theo địa lý
Kết quả tìm kiếm của Google có thể thay đổi tùy theo vị trí địa lý của người dùng. Proxy cho phép bạn mô phỏng các yêu cầu từ các vị trí khác nhau, cung cấp quyền truy cập vào kết quả tìm kiếm bị giới hạn theo địa lý hoặc cục bộ. Điều này đặc biệt hữu ích cho các doanh nghiệp tiến hành nghiên cứu thị trường hoặc phân tích đối thủ cạnh tranh ở nhiều khu vực.
Nâng cao hiệu quả thu thập dữ liệu với Multilogin
Multilogin tăng cường nỗ lực thu thập dữ liệu của bạn bằng cách tích hợp liền mạch với các proxy dân dụng chất lượng cao. Sau đây là cách Multilogin và các proxy hoạt động cùng nhau để đảm bảo thu thập dữ liệu hiệu quả và không bị phát hiện trên Google:
Quản lý hồ sơ: Multilogin cho phép bạn tạo và quản lý nhiều hồ sơ trình duyệt, mỗi hồ sơ có cài đặt proxy riêng. Điều này đảm bảo rằng các yêu cầu của bạn được phân phối trên các địa chỉ IP khác nhau.
Hành vi giống con người: Multilogin mô phỏng hành vi duyệt web của con người, giúp giảm thiểu nguy cơ bị phát hiện.
Xử lý phiên: Quản lý hiệu quả các phiên và cookie để duy trì hoạt động thu thập dữ liệu liên tục mà không bị gián đoạn.
Phương pháp tiếp cận thống nhất để thu thập dữ liệu Google bản đồ và trang tính với Multilogin
Việc thu thập dữ liệu các bản đồ và trang tính Google có thể hợp lý hóa việc trích xuất và tích hợp dữ liệu cho các dự án của bạn. Sau đây là cách bạn có thể thu thập dữ liệu hiệu quả cả hai bằng Multilogin:
Cấu hình Multilogin: Thiết lập nhiều hồ sơ trình duyệt với các cấu hình riêng biệt để đa dạng hóa các hoạt động thu thập dữ liệu của bạn và tránh bị phát hiện.
Phát triển tập lệnh: Sử dụng Python với các thư viện liên quan (Selenium cho Google Bản đồ , gspread cho Google Trang tính) để phát triển các tập lệnh thu thập dữ liệu của bạn. Các thư viện này đơn giản hóa tương tác với các dịch vụ Google tương ứng.
Mô phỏng tương tác của con người: Đảm bảo các tập lệnh của bạn thực hiện các hành động theo cách giống con người để vượt qua các cơ chế chống thu thập dữ liệu của Google. Điều này bao gồm việc ngẫu nhiên hóa các chuyển động của chuột, nhấp chuột và các mẫu nhập..
Quản lý phiên và cookie: Sử dụng các tính năng quản lý phiên và cookie nâng cao của Multilogin để duy trì nhiều tác vụ thu thập dữ liệu đồng thời mà không bị phát hiện.
Thực thi và giám sát liên tục: Chạy các tập lệnh của bạn trong Multilogin, theo dõi chặt chẽ và thực hiện các điều chỉnh cần thiết để nâng cao hiệu suất và độ tin cậy.
Bằng cách làm theo các bước hợp lý này, bạn có thể thu thập dữ liệu từ Google Trang tính và Google bản đồ một cách hiệu quả, đồng thời tận dụng các tính năng mạnh mẽ của Multilogin để đảm bảo các hoạt động liền mạch và không bị phát hiện.
Best Practices for Scraping Google Search Results
Avoid Detection with Multilogin
Để thu thập dữ liệu từ Google thành công mà không bị phát hiện, hãy làm theo các biện pháp tốt nhất sau và sử dụng các công cụ như Multilogin:
Mô phỏng hành vi của con người: Ngẫu nhiên hóa chuyển động của chuột, nhấp chuột và kiểu gõ.
Xoay vòng địa chỉ IP: Sử dụng proxy dân cư do Multilogin cung cấp để xoay vòng địa chỉ IP và tránh bị phát hiện.
Quản lý hồ sơ trình duyệt: Sử dụng Multilogin để tạo và quản lý nhiều hồ sơ trình duyệt, mỗi hồ sơ có cấu hình riêng.
Tuân thủ giới hạn tỷ lệ: Tránh gửi quá nhiều yêu cầu trong thời gian ngắn để tránh kích hoạt các biện pháp chống bot của Google từ một tài khoản duy nhất.
Theo dõi hiệu suất: Kiểm tra thường xuyên hiệu suất của các tập lệnh thu thập dữ liệu của bạn và thực hiện các điều chỉnh khi cần thiết.