

绕过机器人检测
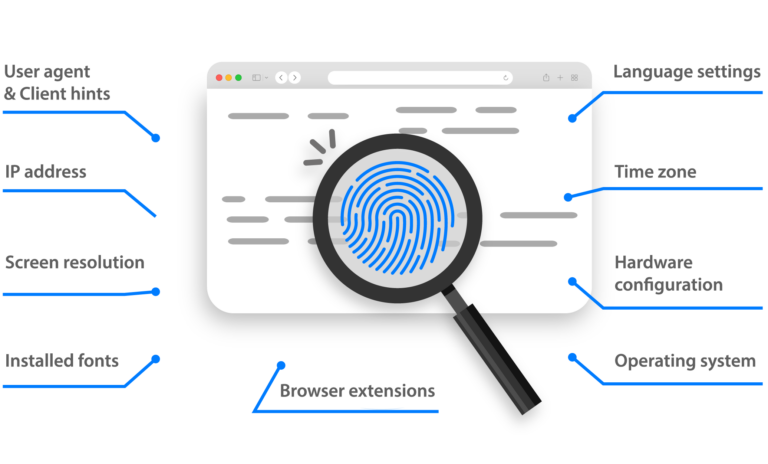
我们的防指纹技术通过掩盖唯一的浏览器指纹,绕过多账号和浏览器自动化检测。

与主流的自动化工具集成
使用Selenium、Playwright和Puppeteer执行自动化数据抓取,同时保持它们对反自动化机器人的隐身性。

通过云端同步数据
使用云浏览器配置文件在多个设备或VPS实例之间同步数据。

调整浏览器指纹以匹配代理
自动调整浏览器指纹以匹配代理位置,支持所有代理类型以增强安全性。

支持所有类型的代理
使用我们的代理或您自己的代理。我们支持所有代理类型。

简便的容器化
使用我们的快速容器化指南轻松地将您的网络抓取实例容器化。

全功能浏览器
不同于容易被检测为抓取机器人的无头浏览器,我们的浏览器模仿真实的Chrome和 Firefox活动,避免网站限制。

无头浏览器
无头浏览器速度更快且轻便,非常适合高速抓取。在您自己的设备上运行它们,以获得更大的控制和性能。












注册
使用经过验证的邮箱地址注册。

选择您的方案
从多种订阅方案中选择,这些方案根据您的需求量身定制。

下载Multilogin Agent
支持Windows、Mac和Linux。

访问Multilogin操作界面
开始创建和管理防检测浏览器配置文件。

运行您的数据抓取脚本
整合您的Puppeteer、Selenium和Playwright数据抓取脚本,并开始收集数据。