

Các hệ thống bảo vệ website ngày càng trở nên phức tạp, và Cloudflare là một trong những giải pháp phổ biến nhất hiện nay. Cloudflare được sử dụng cả trên các dự án nhỏ lẫn những nền tảng và marketplace lớn. Vì vậy, một câu hỏi hoàn toàn dễ hiểu thường xuyên được đặt ra là: “Làm thế nào để vượt Cloudflare và khôi phục quyền truy cập ổn định?”
Những hạn chế như vậy không chỉ ảnh hưởng đến người dùng thông thường. Vấn đề này đặc biệt nghiêm trọng trong các hoạt động parsing và scraping dữ liệu, arbitrage traffic và làm việc hàng loạt với nhiều tài khoản. Dù mục tiêu sử dụng khác nhau, nguyên nhân bị chặn gần như luôn giống nhau — hệ thống bảo vệ không thể xác định rõ ràng rằng yêu cầu truy cập đến từ một người dùng thật.
Cách nhận biết website đang được bảo vệ bởi Cloudflare
Các hệ thống bảo vệ website ngày càng trở thành nguyên nhân phổ biến gây ra sự cố truy cập. Nếu website không mở được, quá trình tải bị lặp vô hạn hoặc đột ngột xuất hiện kiểm tra bảo mật — trong phần lớn trường hợp, điều này liên quan trực tiếp đến Cloudflare.
Dưới đây là những màn hình chặn và kiểm tra phổ biến nhất mà người dùng thường gặp phải. Nếu bạn từng thấy một trong số đó, rất có thể hệ thống bảo vệ đã không thể xác định yêu cầu của bạn là “an toàn”.
Kiểm tra trình duyệt Cloudflare — trang tạm thời với xác minh môi trường tự động
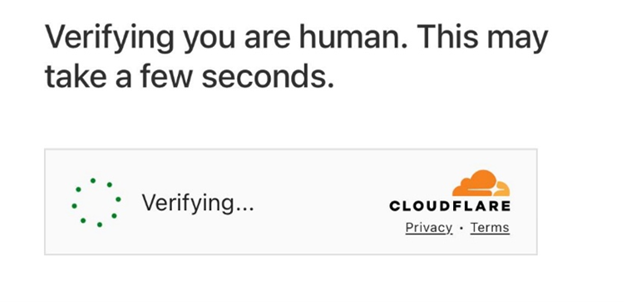
Cloudflare tạm thời kiểm tra trình duyệt và kết nối. Thông thường quá trình này chỉ kéo dài vài giây, nhưng trong trường hợp có vấn đề, nó có thể bị lặp liên tục.
Cloudflare CAPTCHA — xác nhận yêu cầu được thực hiện bởi con người

Website yêu cầu xác nhận rằng truy cập đang được thực hiện bởi con người. Điều này thường xảy ra khi IP bị nghi ngờ hoặc môi trường truy cập không tiêu chuẩn.
Lỗi 1020 / Access Denied — chặn truy cập theo quy tắc bảo mật
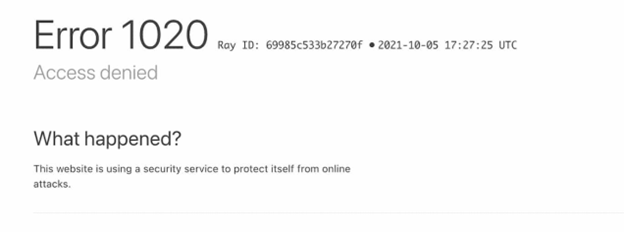
Quyền truy cập vào website bị từ chối do các quy tắc bảo mật. Nguyên nhân phổ biến nhất liên quan đến IP hoặc các hành động mang tính tự động.
Mặc dù giao diện hiển thị khác nhau, tất cả các trang này đều có chung một nguyên nhân: Cloudflare không tin tưởng môi trường kỹ thuật của yêu cầu truy cập. Hệ thống hầu như không bao giờ cho biết chính xác tham số nào đã kích hoạt hạn chế.
Hiểu Cách Vượt Cloudflare: Vì sao Cloudflare chặn truy cập website
Các cơ chế bảo vệ của Cloudflare hoạt động dựa trên đánh giá rủi ro. Nếu hành vi hoặc yêu cầu truy cập có dấu hiệu bất thường, hệ thống sẽ áp dụng các biện pháp hạn chế. Cloudflare không chặn vì một hành động đơn lẻ, mà dựa trên tổng hợp nhiều tín hiệu cho thấy khả năng tự động hóa hoặc lạm dụng.
Những yếu tố cụ thể gây ra chặn Cloudflare
Các tín hiệu nguy hiểm bao gồm IP không ổn định, sự không khớp giữa IP và fingerprint trình duyệt, header HTTP bất thường, tần suất lặp lại cao và khoảng thời gian giữa các yêu cầu không tự nhiên.
Cloudflare không công bố lý do chính xác của việc chặn. Tuy nhiên, dựa vào loại kiểm tra hoặc mã lỗi, có thể xác định khá chính xác yếu tố nào đã gây ra hạn chế. Dưới đây là bảng minh họa mối liên hệ giữa nguyên nhân, phản ứng của Cloudflare và những gì người dùng nhìn thấy.
| Nguyên nhân | Phản ứng của Cloudflare | Những gì người dùng thấy |
| Danh tiếng IP đáng ngờ | Kiểm tra trình duyệt | Trang Checking your browser before accessing |
| IP không khớp fingerprint trình duyệt | Kiểm tra lặp lại | Quá trình kiểm tra chạy liên tục |
| Thông số trình duyệt không tiêu chuẩn | CAPTCHA | Yêu cầu xác nhận bạn là con người |
| Hành động hàng loạt hoặc lặp lại | Rate Limiting | Tải chậm hoặc lỗi tạm thời |
| Yêu cầu tự động hóa | Bot Protection | CAPTCHA hoặc chặn ngầm |
| Vi phạm quy tắc bảo mật website | WAF Rule | Lỗi 1020 Access Denied |
| Thiếu cookie / phiên làm việc | Session Check | Phiên bị reset mỗi lần tải lại |
| HTTP header bất thường | Security Filter | Từ chối truy cập không giải thích |
Cần hiểu rằng Cloudflare hiếm khi phản ứng với một tham số duy nhất. Thông thường, quyết định được đưa ra dựa trên tổng hợp nhiều yếu tố, và kết quả bên ngoài — CAPTCHA, kiểm tra hay lỗi truy cập — chỉ phản ánh đánh giá rủi ro cuối cùng.
Bị chặn ngay cả khi sử dụng website bình thường
Ngay cả khi không sử dụng tự động hóa, Cloudflare vẫn có thể chặn truy cập. Điều này thường xảy ra khi dùng trình duyệt không phổ biến, extension đặc biệt, proxy hoặc mạng không ổn định. Cloudflare phản ứng không dựa trên ý định người dùng, mà dựa trên môi trường kỹ thuật.
Vì sao khi parsing và scraping bị chặn nhiều hơn
Trong parsing và scraping, tình hình càng phức tạp hơn. Cloudflare chặn các yêu cầu này nhanh hơn vì chúng lặp lại, có pattern giống nhau và thiếu hành vi người dùng tự nhiên. Ngay cả scraping cẩn thận, không gây tải lớn, vẫn có thể bị coi là đáng ngờ.
Cloudflare chống bot và tự động hóa hoạt động như thế nào
Để hiểu cách vượt Cloudflare, cần nhớ rằng hệ thống không chỉ phân tích IP. Cơ chế anti-bot của Cloudflare đánh giá toàn bộ môi trường trình duyệt.
Hệ thống xem xét:
- fingerprint trình duyệt;
- tập HTTP header;
- lịch sử phiên;
- hành vi người dùng trên trang;
- sự nhất quán giữa IP, vị trí địa lý và thiết bị.
Kiểm tra bảo mật có thể diễn ra ngay lập tức hoặc sau một số hành động thành công nếu phát hiện bất thường.
Quy tắc bảo vệ động và phân tích lưu lượng
Cloudflare sử dụng các quy tắc động được cập nhật theo thời gian thực. Hệ thống phân tích lưu lượng để phát hiện các dấu hiệu tấn công: xâm nhập, vi phạm giao thức, pattern yêu cầu đáng ngờ, lỗi server và tải cache bất thường.
Khi phát hiện mối đe dọa, các chữ ký độc nhất được tạo và phân phối trên toàn mạng, giúp chặn lưu lượng nguy hiểm ở quy mô toàn cầu mà gần như không ảnh hưởng đến người dùng hợp pháp.
Phản ứng nhanh và lọc nhiều lớp
Một trong những ưu điểm lớn của Cloudflare là tốc độ phản ứng. Các cuộc tấn công mạng được chặn trong vài giây, còn các mối đe dọa HTTP được xử lý chỉ trong vài chục giây.
Hệ thống lọc giúp ngăn chặn lưu lượng nguy hiểm trước khi nó tiếp cận máy chủ gốc.
Bypass Cloudflare: vì sao cần cách vượt Cloudflare hiệu quả
Việc vượt Cloudflare hiệu quả không thể đạt được chỉ với một công cụ đơn lẻ. Điều này đòi hỏi sự đồng bộ giữa trình duyệt, IP, thiết bị và hành vi.
Nguyên tắc này áp dụng cho:
- người dùng thông thường;
- doanh nghiệp và đội nhóm;
- parsing và scraping dữ liệu;
- arbitrage traffic và multi-account.
Vì sao các phương pháp đơn lẻ không hiệu quả
Nếu chỉ thay IP, Cloudflare sẽ phát hiện vấn đề ở trình duyệt. Nếu dùng tự động hóa mà không có môi trường trình duyệt hoàn chỉnh, hệ thống sẽ tiếp tục hạn chế truy cập. Kết quả ổn định chỉ đạt được khi kiểm soát toàn bộ chuỗi tham số.
Parsing và scraping dưới lớp bảo vệ Cloudflare
Khi parsing, website đặc biệt nhạy cảm với các hành động lặp lại. Cloudflare chặn IP nếu lưu lượng mang tính hàng loạt và liên kết với nhau. Chỉ một lỗi cấu hình nhỏ cũng có thể khiến quá trình thu thập dữ liệu bị dừng hoàn toàn.
Để scraping ổn định, cần:
- Cách ly các phiên trình duyệt;
- Fingerprint chân thực;
- Sự nhất quán giữa vị trí địa lý và thiết bị;
- Kiểm soát tốc độ và trình tự hành động.
Nếu không đáp ứng các điều kiện này, việc parsing sẽ thiếu ổn định và cần can thiệp thủ công liên tục.
Giả lập trình duyệt và tự động hóa
Các công cụ như Playwright, Puppeteer và Selenium cho phép tái hiện hành vi người dùng thật. Tuy nhiên, bản thân tự động hóa không giải quyết được vấn đề — yếu tố quyết định nằm ở cấu hình môi trường trình duyệt.
Nếu không được điều chỉnh, các công cụ này rất dễ bị phát hiện. Vì vậy, cần áp dụng các phương pháp che giấu để đưa tham số trình duyệt về gần hành vi người dùng thật, từ đó giảm nguy cơ kích hoạt kiểm tra bổ sung.
Luân chuyển proxy và quản lý IP
Luân chuyển proxy là cần thiết để tránh bị phát hiện qua IP. Hiệu quả nhất là proxy residential, vì chúng gắn liền với thiết bị thực. Cấu hình luân chuyển hợp lý giúp phân phối lưu lượng đều và giảm nguy cơ bị chặn.
Quan trọng không chỉ là thay IP, mà là thay đổi một cách hợp lý, tránh các pattern đột ngột và không tự nhiên.
Kết hợp nhiều phương pháp để truy cập ổn định
Trên thực tế, kết quả bền vững chỉ đạt được khi kết hợp nhiều phương pháp: luân chuyển IP, che fingerprint trình duyệt, lưu phiên và xử lý CAPTCHA. Tổng thể này khiến lưu lượng khó bị nhận diện và giảm khả năng bị hạn chế.
Multilogin — môi trường toàn diện vượt Cloudflare và hơn thế
Multilogin giải quyết vấn đề một cách tổng thể bằng cách tạo các profile trình duyệt độc lập, được website nhìn nhận như người dùng thật. Điều này cho phép quản lý hơn 100 tài khoản song song, phân bổ parsing hợp lý và tránh trộn lẫn phiên.
Hai engine trình duyệt cho các nền tảng khác nhau
Multilogin cung cấp hai engine:
- Mimic (Chromium) — tương thích với hầu hết website và extension;
- Stealthfox (Firefox) — lựa chọn thay thế cho các nền tảng nhạy cảm với Chromium.
Việc chọn engine khi tạo profile giúp linh hoạt thích ứng với yêu cầu của từng website.
Kịch bản di động và profile Android
Với giả lập Android, bạn có thể mô phỏng trình duyệt di động — tính năng này có sẵn trên tất cả các gói. Điều này đặc biệt quan trọng khi scraping feed, phiên bản mobile của website và ứng dụng, nơi thiết bị ảnh hưởng trực tiếp đến quyền truy cập.
IP, proxy và địa lý khi làm việc với Cloudflare
Cloudflare liên tục chặn IP, đặc biệt nhanh khi có hành động hàng loạt. Multilogin cung cấp hạ tầng proxy residential tích hợp tại hơn 150 quốc gia và 1400+ thành phố, hỗ trợ luân chuyển và phiên tĩnh lên đến 24 giờ.
Ưu điểm then chốt là tự động đồng bộ fingerprint trình duyệt với vị trí proxy, loại bỏ vấn đề không khớp IP–môi trường — nguyên nhân chính gây ra kiểm tra Cloudflare vô hạn.
Tự động hóa, parsing và làm việc nhóm
Đối với các dự án quy mô lớn, Multilogin hỗ trợ Selenium, Puppeteer, Playwright và Postman, cùng API và cloud profile. Điều này cho phép chạy parsing, warm-up tài khoản và các quy trình khác trong chế độ headless mà vẫn duy trì tính ổn định.
Các tính năng làm việc nhóm, phân quyền và audit giúp quản lý hiệu quả các hệ thống tài khoản lớn và thực hiện A/B testing.
Những sai lầm phổ biến khi cố gắng vượt Cloudflare
Sai lầm phổ biến nhất là cố gắng bypass Cloudflare chỉ bằng proxy hoặc chỉ bằng tự động hóa. Nếu không cách ly profile và kiểm soát fingerprint, các phương pháp này sẽ dẫn đến chặn lặp lại.
Ngoài ra, nhiều người bỏ qua kịch bản di động và engine trình duyệt thay thế, trong khi đây có thể là chìa khóa để truy cập ổn định.
Cách tiếp cận có trách nhiệm và đạo đức khi làm việc với website được Cloudflare bảo vệ
Khi làm việc với các tài nguyên được Cloudflare bảo vệ, cần cân nhắc không chỉ khả năng kỹ thuật mà còn trách nhiệm pháp lý và đạo đức. Mọi phương pháp vượt Cloudflare nên được áp dụng một cách có ý thức và tuân thủ luật pháp hiện hành.
Trong tự động hóa và parsing, cần tuân thủ điều khoản sử dụng của website và xử lý dữ liệu một cách hợp pháp, tránh thu thập trái phép thông tin nhạy cảm. Đồng thời, cần phân bổ tải hợp lý để không ảnh hưởng đến sự ổn định của dịch vụ.
Cuối cùng, câu hỏi có thể vượt Cloudflare một cách có đạo đức hay không phụ thuộc vào mục tiêu và cách tiếp cận. Tự động hóa cẩn trọng, scraping có kiểm soát và tôn trọng giới hạn kỹ thuật là nền tảng để xây dựng hoạt động ổn định và bền vững với các tài nguyên được bảo vệ.
=> Multilogin là giải pháp toàn diện giúp bạn quản lý và vận hành nhiều tài khoản mạng xã hội song song như Facebook, Instagram, Tiktok, Zalo, Shopee,… Công cụ này giúp giảm thiểu rủi ro bị khóa tài khoản, hỗ trợ truy cập và thu thập dữ liệu ổn định mà không bị phát hiện.
