

Bảo vệ vòng lặp
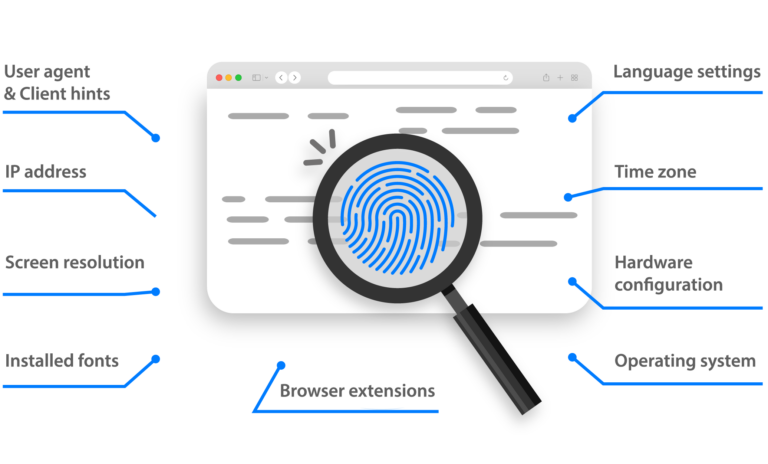
Hơn 55 thông số vân tay có thể tùy chỉnh tạo ra các hồ sơ trình duyệt duy nhất để tránh bị phát hiện. Được kiểm tra hàng ngày trên hơn 50 nền tảng.

Phối hợp đội ngũ
Mời toàn bộ đội ngũ của bạn với quyền truy cập dựa trên vai trò. Chia sẻ hồ sơ, phân công tài khoản dễ dàng.

Đồng bộ hóa dữ liệu qua đám mây
Lưu trữ cookie, tiện ích mở rộng và dữ liệu phiên trong đám mây. Truy cập các hồ sơ của bạn từ bất kỳ thiết bị hoặc máy chủ ảo (VPS) - đồng bộ!

Hỗ trợ lượng tải cao
Hỗ trợ từ 10 đến 10.000 hồ sơ trình duyệt. Multilogin xử lý các hoạt động doanh nghiệp với giới hạn tốc độ API lên đến 100 RPM - cực cao.

Tất cả các loại proxy được hỗ trợ
Sử dụng proxy tích hợp sẵn hoặc proxy của riêng bạn. Hỗ trợ các giao thức HTTP, HTTPS và SOCKS5. Proxy Traffic Saver giúp tiết kiệm băng thông khi tự động hóa.

Hơn 30M+ địa chỉ IP dân dụng tích hợp sẵn
Truy cập các địa chỉ IP dân cư xoay vòng tại hơn 150+ quốc gia và 1.400+ thành phố. Mỗi gói dịch vụ đều bao gồm lưu lượng proxy miễn phí — sẵn sàng sử dụng tại Mỹ, Trung, Châu Âu.

Trình duyệt Mimic và Stealthfox
Hai trình duyệt: Mimic (Chromium) và Stealthfox (Firefox). Chọn danh tính kỹ thuật số phù hợp nhất với nhu cầu của bạn.

Mô phỏng đám mây Android
Chạy các cấu hình Android gốc (OS 9–15) trên máy tính của bạn. Mô phỏng các thiết bị di động thực tế với tín hiệu chính xác cho các nền tảng ưu tiên di động.












Đăng ký
Đăng ký bằng địa chỉ email đã được xác minh.

Chọn gói của bạn
Lựa chọn từ các gói đăng ký khác nhau được thiết kế phù hợp với nhu cầu kinh doanh của bạn.

Tải xuống ứng dụng Multilogin
Có sẵn cho Windows, Mac và Linux.

Truy cập bảng điều khiển Multilogin
Bắt đầu tạo và quản lý các hồ sơ trình duyệt chống phát hiện.

Chạy script thu thập dữ liệu của bạn
Tích hợp các script thu thập dữ liệu của bạn với Puppeteer, Selenium, và Playwright và bắt đầu thu thập.