
Vượt qua sự bảo vệ của bot
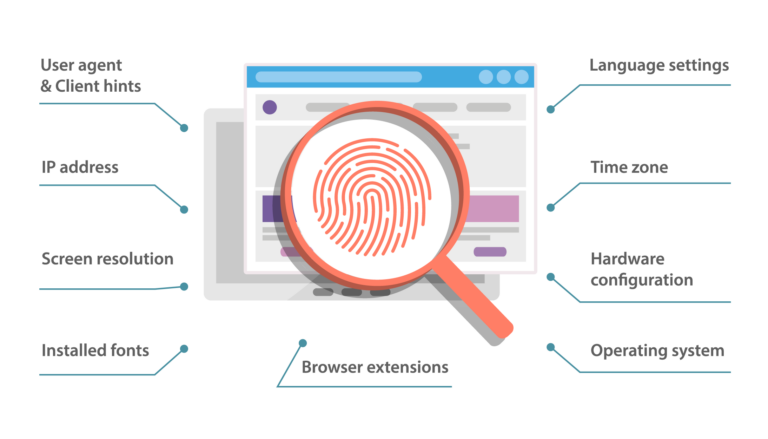
Công nghệ che dấu vân tay của chúng tôi có khả năng sửa đổi nhiều dấu vân tay của trình duyệt để tránh bị phát hiện.

Tích hợp với Selenium, Playwright và Puppeteer
Tự động trích xuất dữ liệu bằng trình điều khiển tự động hóa phổ biến của trình duyệt, đồng thời vẫn ẩn khỏi các bot chống tự động hóa.

Proxy luân phiên dân cư
Truy cập vào các nút proxy dân dụng cao cấp tại hơn 1400 thành phố trên 150 quốc gia với đăng ký Multilogin của bạn.

Điều chỉnh vân tay cho Proxy
Tất cả dấu vân tay của trình duyệt đều được tự động điều chỉnh để phù hợp với vị trí của proxy, giúp tăng cường tính ẩn danh.

Hỗ trợ tất cả các loại Proxy
Cho dù bạn sử dụng proxy của chúng tôi hay tự dùng proxy của mình, mọi loại proxy đều được hỗ trợ liền mạch.

Đồng bộ dữ liệu qua đám mây
Sử dụng cấu hình trình duyệt dựa trên đám mây để đồng bộ hóa dữ liệu liền mạch trên nhiều phiên bản VPS.

Trình duyệt đầy đủ tính năng
Không giống như các trình duyệt không có giao diện dễ bị phát hiện là bot thu thập dữ liệu, trình duyệt của chúng tôi mô phỏng hoạt động thực tế của Chrome và Firefox, ngăn chặn các trang web hạn chế.

Docker hóa dễ dàng
Docker hóa các phiên bản thu thập dữ liệu Facebook của bạn một cách dễ dàng bằng cách sử dụng hướng dẫn Docker hóa nhanh chóng của chúng tôi.

Đăng ký
Đăng ký bằng địa chỉ email đã xác minh

Chọn gói của bạn
Chọn từ nhiều gói đăng ký khác nhau phù hợp với nhu cầu kinh doanh của bạn

Tải xuống Multilogin Agent
Có sẵn cho Windows, Mac và Linux. Nó tự động cài đặt hai trình duyệt chống phát hiện trên máy của bạn, được tối ưu hóa và cấu hình sẵn cho các tác vụ thu thập dữ liệu

Truy cập Bảng điều khiển Multilogin
Bắt đầu tạo và quản lý hồ sơ trình duyệt chống phát hiện

Tạo một tập lệnh thu thập dữ liệu Facebook
Viết một tập lệnh với nhà phát triển của bạn hoặc liên hệ với chúng tôi để được hỗ trợ cá nhân