Web scraping: definition, process, and use cases
Web scraping is the process of collecting data from websites automatically. Instead of manually copying information from a page, you use a script or a web scraping tool to pull what you need—whether that’s product prices, search results, user reviews, or social media content.
At its core, a scraper sends a request to a web page, downloads the content (usually HTML), and extracts specific elements from it—like titles, prices, or descriptions. But scraping isn’t just about pulling data. It’s about doing it efficiently, at scale, and without getting blocked.
Read our latest guide on the best antidetect browsers for web scraping.
Challenges of modern web scraping
Years ago, you could get away with basic Python scripts and a few requests per second. Today, most modern websites use anti-bot systems that look for:
- Repeated IPs or location mismatches
- Headless browser signatures
- Automation patterns (e.g. no mouse movement, fast clicks)
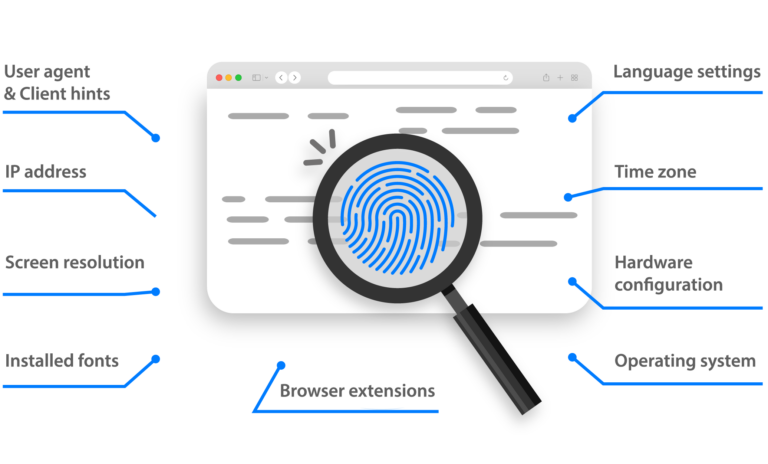
- Duplicate or suspicious browser fingerprints
This means your scraper might get detected before it even starts collecting data. And when that happens, you hit roadblocks—CAPTCHAs, redirects, fake data, or full IP bans.
Multilogin’s role in avoiding scraping blocks
Multilogin is a browser automation and fingerprint control platform designed to make your traffic look like it’s coming from real users. It pairs real browser environments with unique fingerprints and clean residential IPs—so even if you’re scraping at scale, you avoid raising red flags.
You can automate scraping flows with tools like Selenium, Playwright, Puppeteer, or Postman, and Multilogin will handle the browser sessions in the background. Each session runs in isolation with separate cookies, storage, timezones, and user-agent data.
This setup gives you:
- Localized IP and fingerprint combinations
- Persistent logins through sticky sessions
- Reliable results from even the most protected sites
In short: your scrapers stop looking like bots.
Check our guide on how to use residential proxies.
Web scraping in Python
Python is one of the most popular languages for web scraping because of its simplicity and powerful libraries. Whether you’re using BeautifulSoup, Scrapy, or Requests, Python makes it easy to send requests, parse HTML, and export your data.
If you’re scraping dynamic sites (sites that load content with JavaScript), you’ll need a browser automation tool. That’s where Selenium web scraping comes in.
With Selenium, you can control an actual browser (like Chrome or Firefox), click buttons, fill out forms, and scroll pages—just like a human would. This helps when you’re trying to collect data that only appears after user interaction.
Multilogin works well with Python scripts and automation libraries. It lets you create separate browser profiles that your Python code can launch and manage through the API. That means you can rotate between different fingerprints and IPs while your script is running—no manual switching or workarounds needed.
Key features of an effective web scraping tool
Not all scraping tools are built the same. A solid tool should help you:
- Support JavaScript-heavy pages
- Rotate IPs and fingerprints
- Automate browsers reliably
- Integrate with your existing stack (Postman, APIs, headless containers)
Multilogin covers all of that. You can bring your own proxies or use its built-in pool of residential IPs. It works with your favorite automation drivers. And it helps you avoid common scraping issues like broken sessions, CAPTCHA loops, and incomplete data.
Use cases for modern data scraping
Web scraping powers real business decisions. Here are just a few examples of how teams use it every day:
- E-commerce: Track product listings, reviews, prices, and stock levels across marketplaces
- SEO and marketing: Monitor search rankings, competitor content, and paid ads
- Social media: Gather posts, comments, trends, and profile data
- Research and R&D: Collect large datasets to train AI/ML models or monitor public opinion
- Finance: Pull stock prices, news sentiment, or economic indicators from multiple sources
- Real estate: Track listings, rental prices, and availability across regions
All of these require scraping at scale—without being blocked, banned, or served fake content. That’s where having the right setup, including fingerprinting control and rotating proxies, becomes non-negotiable.
Web scraping API
A web scraping API is a tool that provides a simple way to extract data from websites. It handles the complicated parts of web scraping for you. Multilogin works with various APIs to improve your data scraping and give you reliable access to web data.
JavaScript web scraping
JavaScript web scraping focuses on websites that load content dynamically through scripts rather than static HTML. These sites require more advanced scraping setups, since standard tools often miss the data hidden behind JavaScript rendering. Multilogin’s antidetect browsers are designed to handle such environments, ensuring you can access, render, and extract all the necessary information without missing key elements.
Why automation needs more than just a browser
If you’re serious about scraping, you need more than just code. You need infrastructure that helps you scale without hitting walls.
Multilogin offers:
- Full browser fingerprint customization (OS, fonts, languages, WebGL, resolution, etc.)
- API access to launch and manage sessions automatically
- Sticky or rotating proxy support for long-term tasks
- Session isolation so cookies, storage, and cache don’t leak across tasks
- Compatibility with tools like Postman, Puppeteer, Selenium, and Playwright
You can run multiple scraping bots from a single machine—each with its own identity—while keeping everything clean and detectable only as real users.
Multilogin’s impact on web scraping success rates
Multilogin improves your scraping reliability by making each browser session look like a real, independent user. Instead of using generic user-agents or headless browsers that raise red flags, Multilogin assigns a unique fingerprint and a clean residential IP to every session. This drastically reduces the chances of being detected, blocked, or served fake data—especially when targeting sites with strong anti-bot systems. When paired with automation tools like Puppeteer, Playwright, or Selenium, you can scale your scraping without running into walls.
Key ways Multilogin increases scraping success:
Unique browser fingerprints for every session
Built-in residential proxies with 95%+ clean IPs
24-hour sticky sessions to maintain logins and prevent timeouts
Fingerprint matching to your proxy location (timezone, language, OS)
Works with leading scraping tools like Puppeteer, Postman, Playwright, and Selenium
API support for launching sessions and rotating identities automatically
Full-browser rendering for handling JavaScript-heavy websites
Low block rates on high-risk targets like e-commerce, social, and search platforms