Scraping Google search results is a powerful technique for gathering valuable data from the world’s most popular search engine. Whether you want to gain insights, build applications, or compile research data, scraping Google can be incredibly beneficial. This article explores the various aspects of Google scraping, the tools available, and how to effectively use an antidetect browser like Multilogin to avoid detection and ensure smooth operations.
What is Google Scraping?
Google scraping involves extracting data from Google’s search engine results pages (SERPs), Google Maps, and other Google services. This data is useful for SEO analysis, competitor research, market analysis, and more.
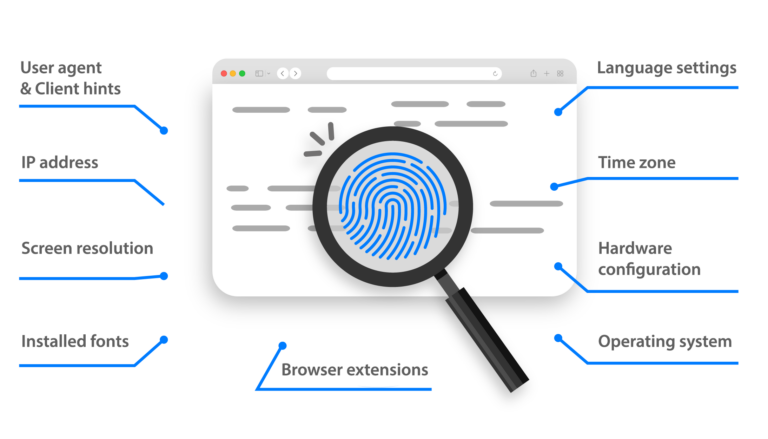
Multilogin allows you to scrape data without triggering CAPTCHAs and avoid issues like IP address blocks. It creates unique digital fingerprints and mimics real browser behavior, making it harder for Google to detect scraping activities.
Is Scraping Google Legal?
The legality of scraping Google is complex. While Google’s terms of service prohibit automated scraping, the act itself is not necessarily illegal. It’s essential to comply with local laws and regulations and use scraping responsibly to avoid legal issues.
Tools for Google Web Scraping
Google Web Scraping Tools
Several tools can assist with web scraping Google, varying in complexity and functionality to cater to different needs and technical expertise levels.
Custom Python Scripts
Python, with libraries like BeautifulSoup, Scrapy, and Selenium, is a popular choice for web scraping. These libraries provide powerful tools for extracting data from Google search results and Google Maps.
Multilogin: The Antidetect Browser Solution
Multilogin is an antidetect browser that allows you to manage multiple profiles and avoid detection while scraping Google. It simulates human behavior and uses high-quality residential IPs to prevent Google from identifying and blocking your scraping activities.
Does Google Allow Scraping?
Google’s policies generally prohibit scraping its services without prior permission. Specifically, their Terms of Service state that automated access or extraction of data from Google’s services, such as search results, without express consent, is not allowed. Scraping without permission can lead to legal issues.
Google Scraping APIs: Limits and Considerations
Google offers APIs such as the Custom Search JSON API and Places API for accessing search and location data. However, these APIs have usage limits and restrictions, which can hinder extensive scraping projects.
Using Multilogin alongside custom scraping scripts can help you bypass these limitations and access the data you need without hitting API limits. Multilogin masks or alters your digital fingerprints and prevents websites from detecting your activities.
Do You Need Special Google Scraping Proxies?
When it comes to scraping Google search results, using proxies is essential. Here’s why:
Avoiding Detection and Bans
Google has sophisticated systems to detect and block automated scraping. If multiple requests come from the same IP address in a short period, Google can quickly flag and ban the IP. Proxies help distribute your requests across multiple IP addresses, significantly reducing the risk of detection and ensuring your scraping activities remain uninterrupted.
Ensuring Anonymity
Proxies mask your real IP address, providing anonymity and making it harder for Google to trace the requests back to you. This is crucial for maintaining the integrity of your scraping operations, especially if you need to gather large volumes of data.
Accessing Geo-Restricted Data
Google’s search results can vary based on the user’s geographic location. Proxies allow you to simulate requests from different locations, providing access to geo-restricted or localized search results. This is particularly useful for businesses conducting market research or competitor analysis in multiple regions.
Enhancing Scraping Efficiency with Multilogin
Multilogin enhances your scraping efforts by integrating seamlessly with high-quality residential proxies. Here’s how Multilogin and proxies work together to ensure efficient and undetected Google scraping:
Profile Management: Multilogin allows you to create and manage multiple browser profiles, each with its own proxy settings. This ensures distributing your requests across different IP addresses.
Human-Like Behavior: Multilogin mimics human browsing behavior, further reducing the risk of detection.
Session Handling: Efficiently manage sessions and cookies to maintain continuous scraping operations without interruptions.
Unified Approach for Scraping Google Maps and Google Sheets with Multilogin
Scraping Google Maps and Google Sheets can streamline data extraction and integration for your projects. Here’s how you can efficiently scrape both using Multilogin:
Multilogin Configuration: Set up multiple browser profiles with unique configurations to diversify your scraping activities and avoid detection.
Script Development: Use Python with relevant libraries (Selenium for Google Maps, gspread for Google Sheets) to develop your scraping scripts. These libraries simplify interaction with the respective Google services.
Simulate Human Interaction: Ensure your scripts perform actions in a human-like manner to bypass Google’s anti-scraping mechanisms. This includes randomizing mouse movements, clicks, and typing patterns.
Session and Cookie Management: Utilize Multilogin’s advanced session and cookie management features to maintain multiple concurrent scraping tasks without detection.
Execution and Continuous Monitoring: Run your scripts within Multilogin, keeping a close watch and making necessary adjustments to enhance performance and reliability.
By following these streamlined steps, you can efficiently scrape Google Sheets and Google Maps while leveraging Multilogin’s robust features to ensure seamless and undetected operations.
Best Practices for Scraping Google Search Results
Avoid Detection with Multilogin
To successfully scrape Google without detection, follow these best practices and use tools like Multilogin:
Mimic Human Behavior: Randomize mouse movements, clicks, and typing patterns.
Rotate IP Addresses: Use residential proxies provided by Multilogin to rotate IP addresses and avoid detection.
Manage Browser Profiles: Utilize Multilogin to create and manage multiple browser profiles, each with unique configurations.
Respect Rate Limits: Avoid sending too many requests in a short period to prevent triggering Google’s anti-bot measures from a single account.
Monitor Performance: Regularly check the performance of your scraping scripts and make adjustments as needed.