






Bypass bot detection
Our anti-fingerprinting tech bypasses multi-account and automated browser detection by masking unique browser fingerprints.

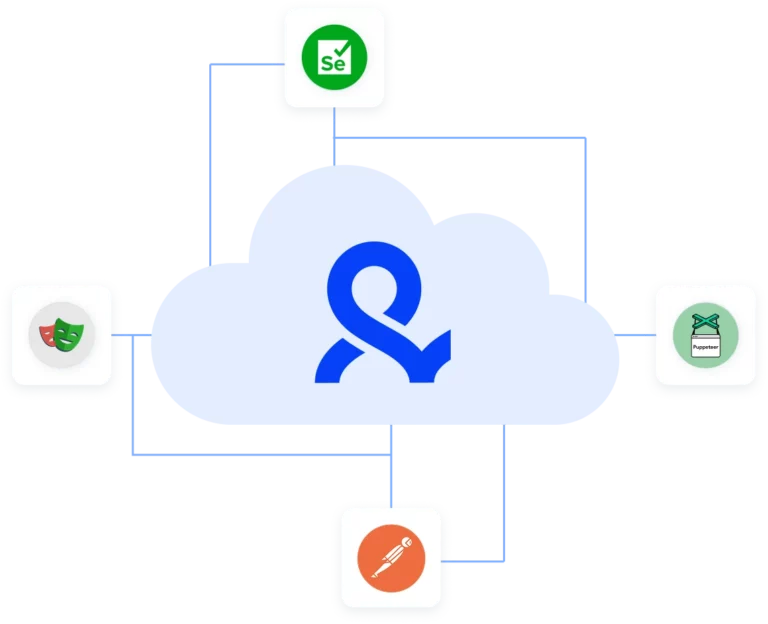
Integration with Selenium, Playwright, and Puppeteer
Automate data extraction with popular browser automation drivers all while keeping them invisible to anti-automation bots.

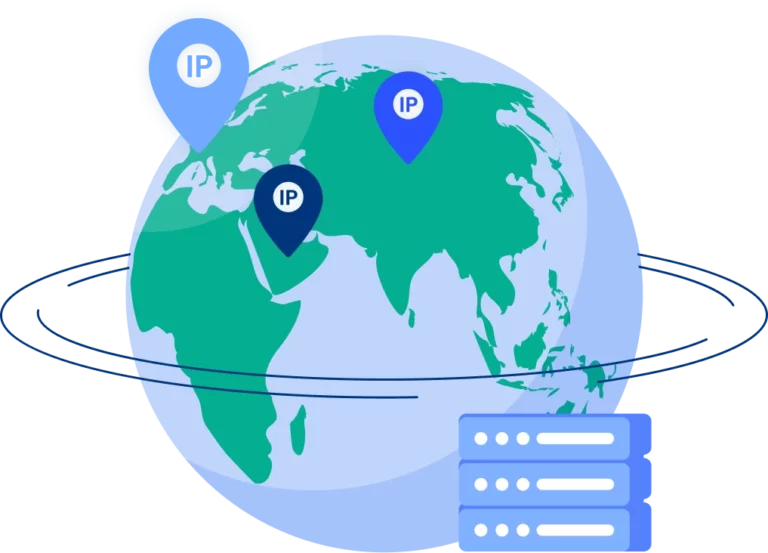
Residential rotating proxies
Gain access to premium residential proxy nodes in 1400+ cities across 150+ countries with your Multilogin subscription.

Fingerprint adjustment to proxies
Our system automatically adjusts all browser fingerprints to match the proxy’s location to enhance anonymity.

Support for all proxy types
Use our proxies or bring your own. Multilogin supports all proxy types.

Data sync over VPS
Use our cloud profiles to synchronize data across multiple VPS instances effortlessly.

Fully featured browsers
Our browsers mimic real user activity to prevent website restrictions, unlike other headless browsers.

Easy dockerization
Dockerize your scraping instances with ease using our quick dockerization guide.












Sign up
Register using a verified email address.

Choose your plan
Select from various subscription plans tailored to your business needs.

Download Multilogin agent
Available for Windows, Mac, and Linux.

Access the Multilogin dashboard
Start creating and managing antidetect browser profiles.

Run your data scraping script
Integrate your Puppeteer, Postman, Selenium, and Playwright data scraping scripts and begin collection.